If you’ve spent any time in the API space, you know that the hardest part of integration isn’t the API itself. It’s everything around it. The authentication wiring. The data transformation. The mapping between what an upstream API gives you and what your downstream consumer actually needs. The documentation that gets written once and never updated. The glue code that three people understand and nobody wants to touch.
That’s the problem the Naftiko Capability Specification is designed to solve.
What Is a Capability?
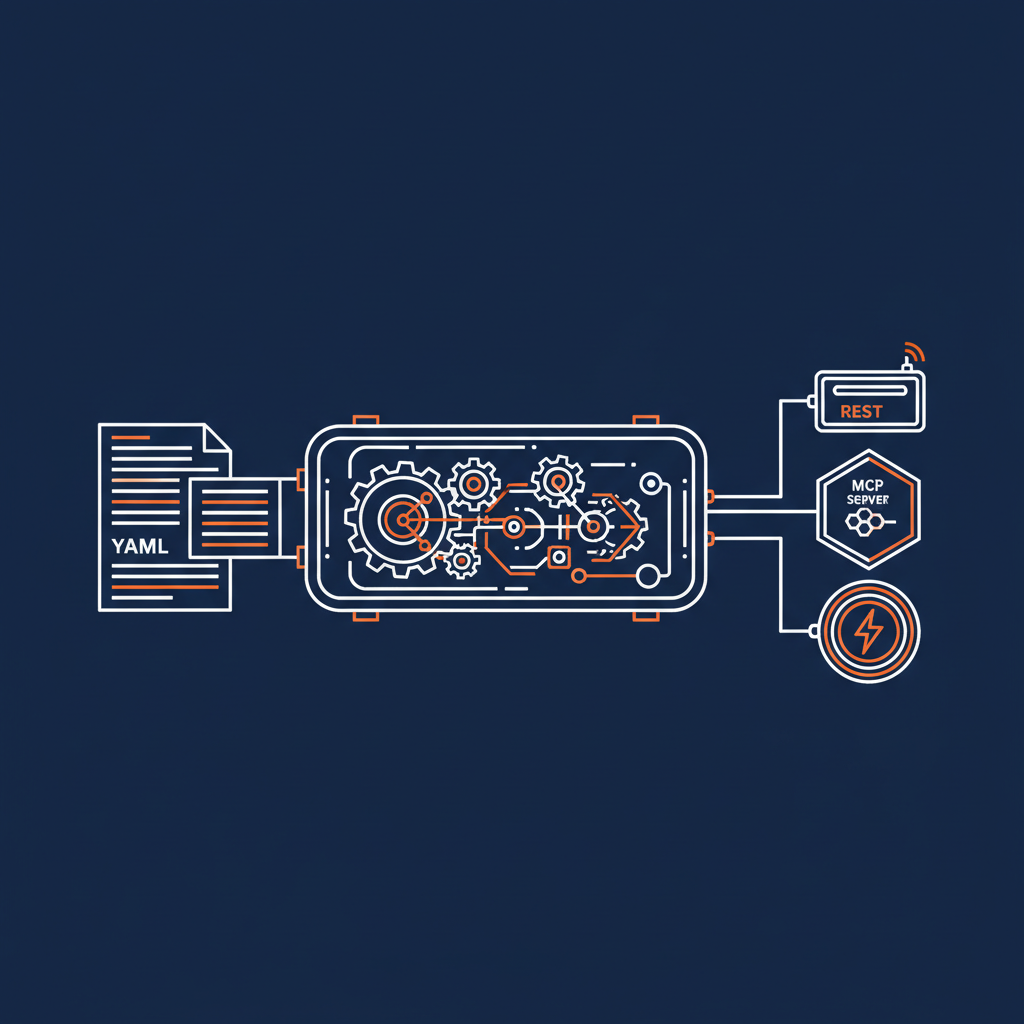
At its core, a capability is a modular, composable integration unit. It declares two things: what it consumes and what it exposes. On the consume side, you’re connecting to existing HTTP APIs — your upstream services, your SaaS providers, your internal microservices. On the expose side, you’re presenting a clean interface that other systems can use — whether that’s a REST API, an MCP server for AI agents, or a skill server for structured discovery.
The specification captures the integration intent, not the implementation details. You write a YAML file that says: here’s what I need from these APIs, here’s how I want to shape and combine that data, and here’s how I want to present it. The Naftiko engine reads that file and handles everything else.
No custom code. No build pipeline. No language runtime. Just a specification and an engine.
The Consume/Expose Duality
This is the architectural idea that makes the whole thing work. Every capability has a consume side and an expose side, and the specification makes the relationship between them explicit and inspectable.
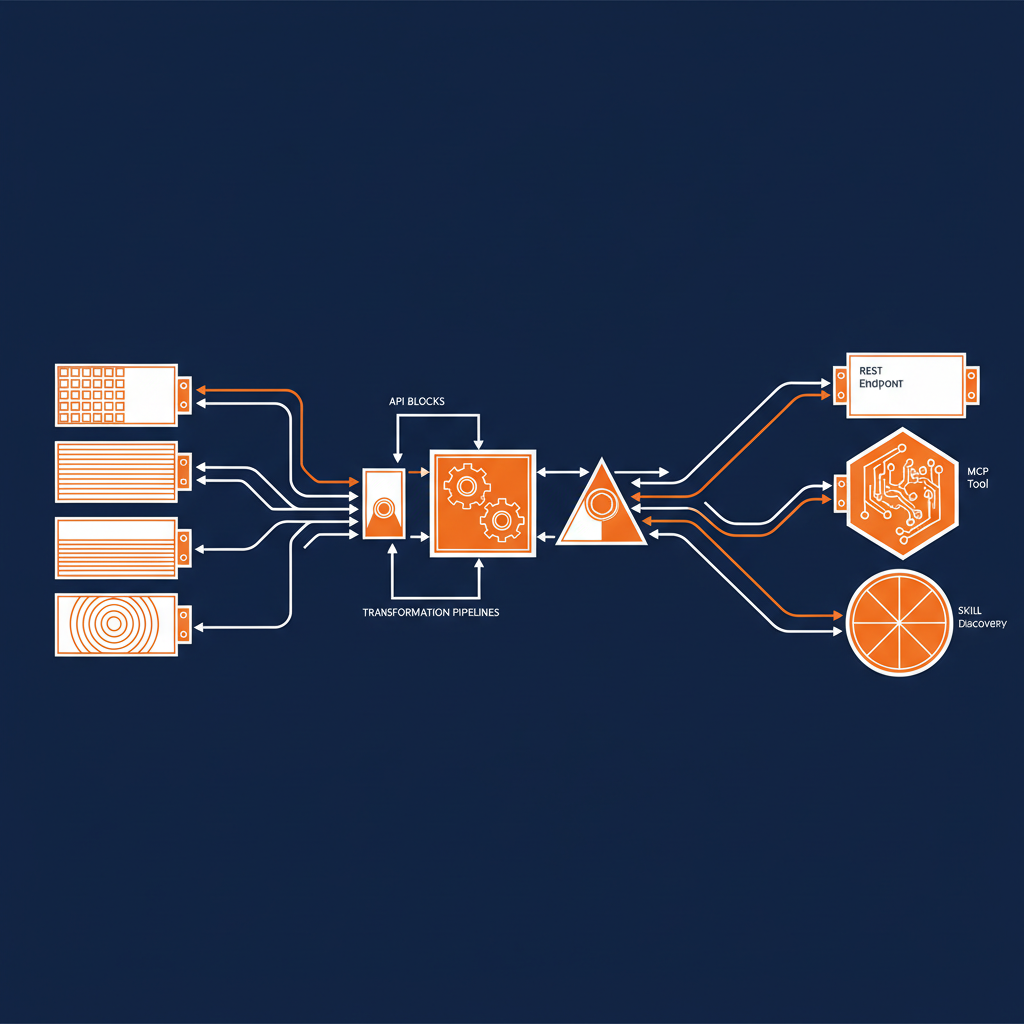
On the consume side, you declare your upstream APIs with their base URIs, authentication, namespaces, resources, and operations. Each consumed source gets a unique namespace, which becomes the routing key that connects it to the expose layer. You’re not just documenting these APIs — you’re declaring a contract with them that the engine can execute.
On the expose side, you choose how to present the capability. A REST expose gives you traditional HTTP endpoints. An MCP expose turns your capability into a set of tools, resources, and prompt templates that AI agents can discover and invoke. A skill expose groups tools into named skills for structured agent discovery. You can expose the same capability multiple ways simultaneously — REST for your existing consumers, MCP for your AI agents, all from the same YAML file.
The bridge between consume and expose is where the real work happens. Each exposed operation references consumed operations through a call field using the format namespace.operationId. You can inject parameters, map outputs with JSONPath expressions, and shape the response to exactly what your consumer needs. For more complex scenarios, you can orchestrate multiple consumed operations into ordered steps, passing data between them, and return a single composed result.
Why YAML and Not Code?
I’ve spent fifteen years watching the API industry cycle through frameworks, SDKs, and integration platforms. The pattern is always the same: you start with a clean abstraction, then the edge cases pile up, and before long you’re writing as much integration code as application code. The abstraction becomes another dependency to manage rather than a simplification.
The Naftiko approach is different because the specification is the integration. There’s no code generation step that introduces drift. There’s no SDK that locks you into a language. The YAML file is a complete, self-contained description of what the integration does, and the engine interprets it directly at runtime.
This matters for governance. When your integration is a YAML file, you can lint it, validate it against a schema, diff it in a pull request, and review it without understanding any particular programming language. You can see exactly what data is being consumed, how it’s being transformed, and what’s being exposed. The specification becomes an inspectable artifact that everyone — developers, architects, security teams, and yes, AI agents — can reason about.
The AI Native Angle
Here’s where things get particularly interesting. The specification was designed from the ground up with AI integration in mind. When you expose a capability as an MCP server, you’re not bolting AI support onto an existing integration framework. You’re declaring tools with names, descriptions, and typed input parameters that become the tool’s JSON Schema. You’re writing descriptions that help agents discover and understand what the capability does. You’re shaping output parameters so agents get exactly the context they need — no more, no less.
The specification supports MCP resources for data that agents can read, and MCP prompt templates for reusable, parameterized message templates. It supports both Streamable HTTP transport for remote MCP clients and stdio transport for local IDE and agent integration. All of this is declared in the same YAML file alongside the consume and REST expose configuration.
This is what context engineering looks like when it’s done at the specification level. You’re not writing custom code to filter and reshape API responses for each AI consumer. You’re declaring the right-sized context once, and the engine handles the rest.
Standing on the Shoulders of Specifications
One thing I appreciate about the Naftiko Specification is that it doesn’t pretend the last decade of API specification work didn’t happen. It explicitly acknowledges its debt to OpenAPI, Arazzo, and OpenCollections, and it positions itself in relation to them clearly.
OpenAPI tells you the shape of an API. Arazzo describes the sequence of API calls in a workflow. OpenCollections gives you runnable, shareable collections. Naftiko combines elements of all three into a single specification focused on integration intent — what goes in, what comes out, and how it all connects. The analogy the team uses is that OpenAPI is the parts list, Arazzo is the assembly sequence, OpenCollections is the step-by-step guide you can run, and Naftiko is the product blueprint.
That’s not a replacement story. It’s a composition story. And it’s the right framing for where the industry is headed.
Spec-Driven Integration
The specification is the centerpiece of what Naftiko calls Spec-Driven Integration — the idea that the specification should be the primary integration artifact, not a byproduct. You author the spec, validate it for completeness and consistency, execute it directly against the engine, and refine it based on production feedback. The spec is always the source of truth.
This resonates with everything I’ve been saying about API governance for years. The organizations that treat their API contracts as living, inspectable artifacts are the ones that scale without drowning in technical debt. The ones that treat integration as a code problem end up with sprawl, duplication, and drift. Naftiko is making a bet that the specification approach can work for integration the same way OpenAPI made it work for API documentation and tooling.
What This Means for Enterprise Teams
If you’re running a large enterprise with dozens or hundreds of API integrations, the capability specification gives you a path to consolidation that doesn’t require rewriting everything. You can wrap existing APIs as capabilities, expose them through consistent interfaces, and gradually build a governed layer of composable integration units. Each capability is self-contained, versioned, and deployable as a Docker container.
For teams building AI-powered applications, the MCP and skill expose types mean you can make your enterprise APIs available to AI agents without building custom integration code for each one. You declare what the agent should be able to do, connect it to the APIs it needs, and the engine handles the protocol translation and data shaping.
The Naftiko Capability Specification is at version 0.5 right now, and it’s moving fast. But the core architectural idea — declare your integration intent in a single, inspectable specification and let the engine handle the rest — feels like the right direction for where API integration needs to go. I’ll be watching this closely and writing more as the ecosystem develops.