I wrote recently about the Naftiko Capability Specification — the declarative YAML format that captures integration intent. But a specification without tooling is just a document. What makes the Naftiko approach real is the framework: an open-source runtime engine, a CLI, and a Docker-native deployment model that turns a capability file into a running integration. No code generation. No build pipeline. No language runtime to manage. Just a YAML file and a Docker container.
That’s not an incremental improvement on how we do integration. That’s a fundamentally different operating model.
The Engine: Your Specification Is Your Integration
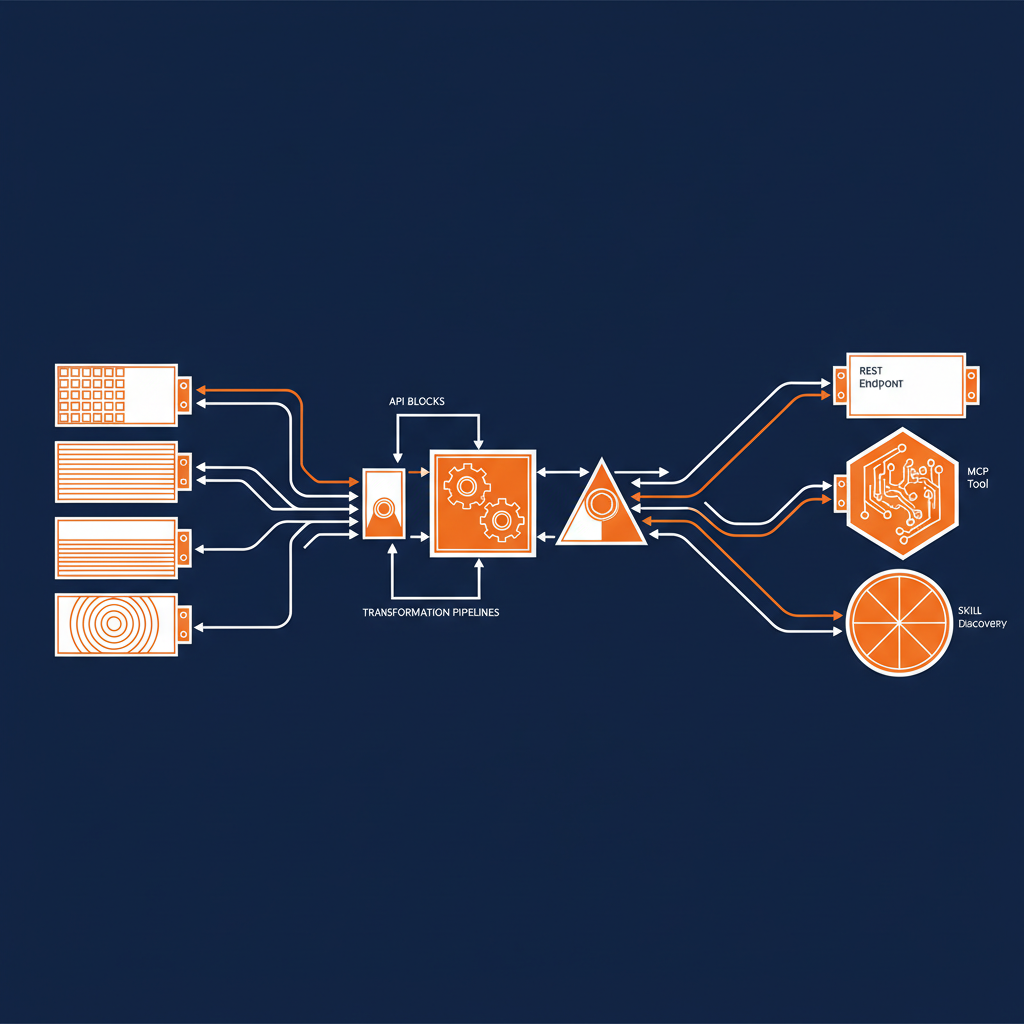
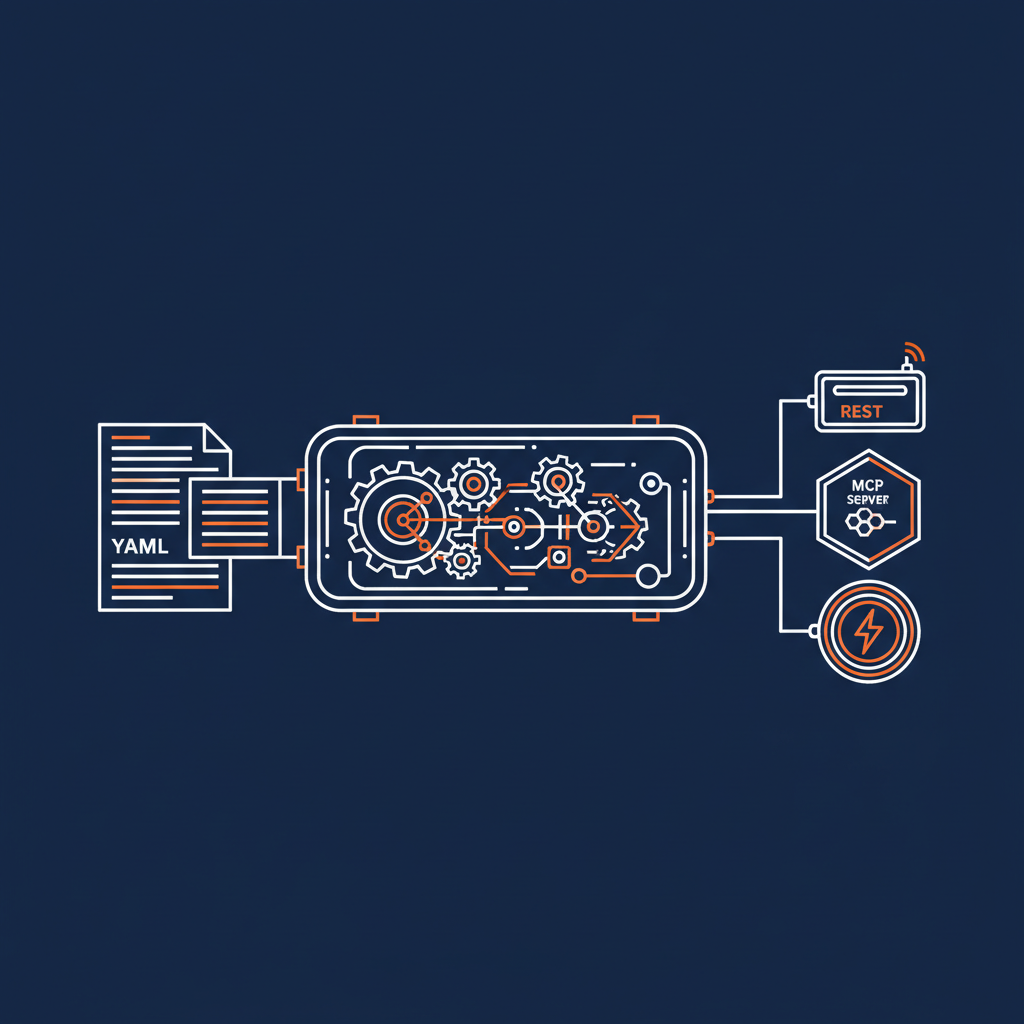
The core of the Naftiko Framework is the engine — a Java-based runtime that reads your capability YAML file at startup and immediately begins serving. You declare what APIs you consume, how you want to transform and compose the data, and what interfaces you want to expose. The engine handles the HTTP consumption, data format conversion, authentication, orchestration, and protocol serving.
This is the key architectural decision that separates Naftiko from code generation approaches. Code generators take a specification and produce source code that you then have to build, test, deploy, and maintain. Every time the spec changes, you regenerate, which introduces drift between what the specification says and what the code actually does. The Naftiko engine eliminates that gap entirely. The specification is interpreted directly at runtime. What you declare is what you get.
The engine supports consuming any HTTP-based API with built-in authentication — bearer tokens, API keys, basic auth, digest auth. It converts between data formats including JSON, XML, YAML, CSV, Avro, and Protobuf. It orchestrates multi-step operations where the output of one API call feeds the input of the next. And it exposes the result through REST endpoints, MCP servers for AI agents, or skill servers for structured agent discovery.
All of that from a YAML file.
Docker Native from Day One
The framework ships as a ready-to-run Docker container. This is a deliberate design choice, not a deployment convenience. When your integration is a YAML file interpreted by a containerized engine, deployment becomes trivial. You mount your capability file into the container, map the ports, pass your secrets as environment variables, and you’re running.
docker run -p 8081:8081 \
-v /path/to/capability.yaml:/app/capability.yaml \
-e GITHUB_TOKEN=ghp_xxx \
ghcr.io/naftiko/framework:latest /app/capability.yaml
That’s it. No Maven builds. No Gradle configurations. No dependency hell. No CI pipeline that takes twenty minutes to produce an artifact. Your capability file is the artifact.
For production, you deploy to Kubernetes with multiple replicas behind a load balancer. The engine’s overhead is minimal — your performance is bounded by the upstream APIs you’re consuming, not by the integration layer. Scale horizontally by adding instances. The engine is stateless; the specification is the only configuration.
The CLI: Create, Validate, Ship
Alongside the engine, the framework provides a CLI tool that handles the developer experience around capability files. Two commands cover most of what you need day to day.
naftiko create capability walks you through creating a valid capability file interactively. It asks questions, generates the YAML, and drops it in your current directory. You’re starting from a valid file rather than staring at a blank editor trying to remember the schema.
naftiko validate checks your capability file against the Naftiko schema and tells you exactly what’s wrong. This is the kind of fast feedback loop that makes spec-driven development practical. You edit the YAML, validate it, fix the errors, and validate again. The iteration cycle is measured in seconds, not minutes.
The CLI currently runs on macOS (Apple Silicon), Linux, and Windows. It’s early — the team has plans for a control port, a web app, and a Docker Desktop extension — but the foundation is solid and the validate command alone saves significant time.
What You Can Build Today
I’ve been tracking the use cases that the framework supports, and the range is broader than you might expect from a v0.5 release.
AI Integration. Declare your upstream APIs in the consume layer, expose them as MCP tools in the expose layer, and AI agents can discover and invoke your capabilities without custom glue code. The framework supports both Streamable HTTP transport for remote MCP clients and stdio transport for local IDE integration. You can expose MCP resources for data that agents can read and prompt templates for reusable message patterns.
Context Engineering. Shape your API responses to deliver exactly the context an AI task needs. Use typed output parameters and JSONPath mapping to filter out irrelevant fields, normalize data structures, and return task-ready payloads. This is what right-sizing AI context looks like when it’s done declaratively.
API Composition. Register multiple consumed APIs with unique namespaces, orchestrate cross-source calls using ordered steps, and return a single composed result. A capability can call the Notion API and the GitHub API in sequence, pass data between them, and expose a unified response that neither API provides on its own.
Microservices Rationalization. If you’re drowning in microservice endpoints, create a simpler capability layer on top. Aggregate multiple services under one exposed namespace, standardize authentication and parameter handling at the capability level, and give your consumers consistent contracts instead of fragmented service interfaces.
API Elevation. Wrap a legacy or poorly designed API as a capability to make it easier to discover, reuse, and consume. Remap HTTP methods to expose proper semantics — turn read-only POST queries into cacheable GETs. Convert XML or CSV payloads to JSON. Add meaningful descriptions for agent discovery. The underlying API doesn’t change; the capability provides a better interface on top.
The Spec-Driven Integration Methodology
The framework implements what Naftiko calls Spec-Driven Integration — a methodology where the specification is the primary integration artifact, not a byproduct. This isn’t just a technical preference. It’s a governance model.
When the specification is the source of truth, you can lint it with tools like Spectral, validate it against a JSON Schema, review it in pull requests without understanding Java or any other language, and track changes through version control. Your integration is inspectable, diffable, and auditable. Try doing that with a thousand lines of custom integration code spread across multiple services.
The workflow is straightforward: specify the integration in YAML, validate it with the CLI, execute it with the engine, and refine based on production feedback. The specification remains the living artifact throughout. There’s no translation layer where intent gets lost.
Where the Framework Is Headed
The roadmap tells an interesting story about where this is going. The first alpha landed on March 30th, 2026, with MCP resources and prompts, skill exposure, lookup steps, consumer authentication, and reusable source capabilities. The second alpha in May adds tool annotations, MCP gateway integration, webhook support, A2A server adapters, conditional and parallel steps, and OpenAPI-to-Naftiko import tooling. The first beta in June focuses on stability, resiliency patterns, and security. General availability is targeted for September.
The trajectory is clear: start with the core consume/expose engine, layer on AI-native protocols, add enterprise-grade reliability and security, and reach production readiness by fall. That’s an aggressive timeline, but the architectural foundation — a spec-interpreted engine with no code generation — means they’re not fighting the complexity that slows down most framework projects.
Why This Matters
I’ve been covering APIs since 2010. I’ve seen every integration pattern, every middleware platform, every attempt to make API consumption easier. Most of them added complexity rather than removing it. Most of them required you to learn their framework before you could do the integration work you actually needed to do.
The Naftiko Framework is the first approach I’ve seen that genuinely reduces the surface area of integration to its essential elements: what do you consume, what do you expose, and how do you connect them. Everything else is handled by the engine. Your YAML file is small enough to read in a sitting, precise enough to execute without interpretation, and portable enough to deploy anywhere Docker runs.
If you’re an enterprise team managing dozens of API integrations, a developer building AI-powered applications, or an architect trying to rationalize microservice sprawl, the Naftiko Framework is worth your attention. Pull the Docker image, write a Hello World capability, and see what happens when your integration is a specification rather than a codebase.