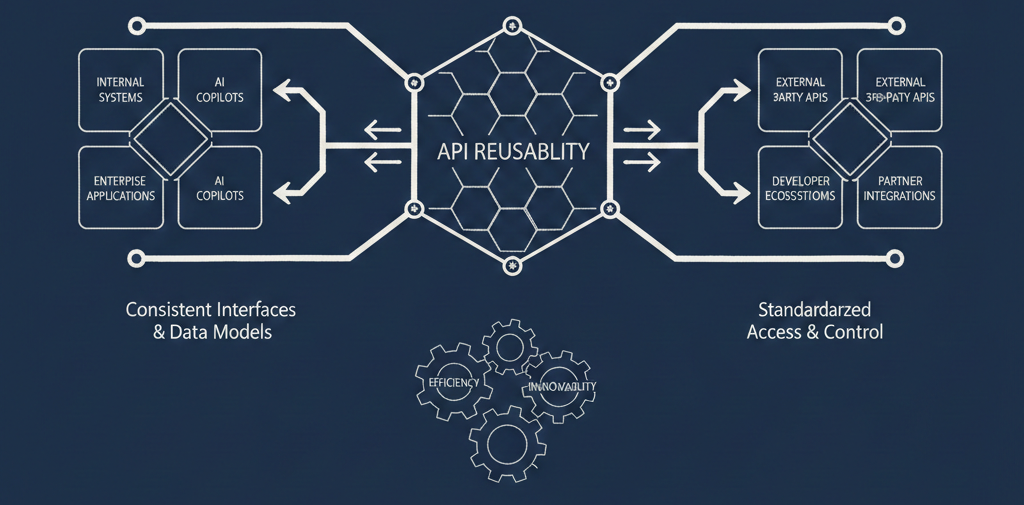
“We need API reusability.”
That mandate shows up in almost every organization eventually. It usually comes wrapped in strategic language: velocity, efficiency, reduced risk, and the ever-present pressure to do more with less. CTOs and CEOs want to see progress through visible metrics — reuse counts, lead time reductions, throughput improvements, maybe even revenue attribution.
And yet, despite years of investment in catalogs, governance programs, and scoring models, API reusability stubbornly refuses to deliver on its promise.
After digging through research and dozens of conversations, one thing has become clear: API reusability is not failing because teams don’t want to reuse. It’s failing because organizations misunderstand what reuse actually depends on.
The Core Tension: Business Narratives vs. Engineering Reality
At the heart of the problem is a familiar disconnect.
From a product and leadership perspective, API reuse is framed as a strategic asset. It’s something you can talk about in press releases, board decks, and transformation narratives. Reuse is supposed to unlock faster delivery, enable new business models, and compound value over time.
From an engineering perspective, reuse lives in the weeds: OpenAPI specs, schemas, auth flows, versioning strategies, and brittle dependencies. Engineers know that simply exposing an endpoint doesn’t make it reusable — especially if it’s undocumented, unstable, or locked behind tribal knowledge.
Meanwhile, the platform and operations perspective worries about sustainability: governance, security, support models, uptime, and ownership. An API that looks reusable on paper but can’t be safely exposed or reliably operated becomes a liability.
Most reuse initiatives fail because they try to collapse these perspectives into a single number.
The Fundamental Discovery Problem
One of the biggest revelations from these conversations is this: API reusability is not primarily a governance problem. It’s a discoverability problem.
Teams already know how to reuse software. They do it every day with open source libraries and cloud services. When developers need a solution, they search, evaluate, and adopt what already exists.
Internal APIs fail this test.
Documentation is scattered across wikis, repos, and slide decks. Links break. URLs change. Context gets lost. Tools like Backstage or API gateways can help, but they’re rarely optimized around problem-driven discovery. Developers can’t easily answer the question: “Does something already exist that solves my problem?”
So teams build again — not because they’re reckless, but because reuse is invisible.
The Reusability Definition Crisis
When organizations do measure reusability, they often reduce it to a counting exercise:
- How many paths are reused?
- How many schemas appear in multiple APIs?
- How many response patterns look similar?
These numbers create the illusion of rigor, but they miss the point. Reuse only matters if it changes outcomes.
Real reusability depends on far more than technical similarity:
- Can teams find the API using business or problem keywords?
- Does the documentation explain real behavior, not just endpoints?
- Is the domain context clear, or are semantics overloaded across teams?
- Can the API be safely exposed outside its original team?
- Is it reliable enough that teams trust it?
- Is there a support and escalation model when things go wrong?
From a product perspective, a reusable API isn’t a disposable artifact — it’s a capability that survives multiple roadmaps and delivers outcomes across products, partners, and automation. Trust, not novelty, is what drives adoption.
Why Taxonomies and Scoring Models Keep Failing
Many organizations attempt to fix reusability with elaborate taxonomies and maturity models. They define reuse “types,” “levels,” and multi-axis scoring systems.
These approaches tend to collapse under real-world complexity.
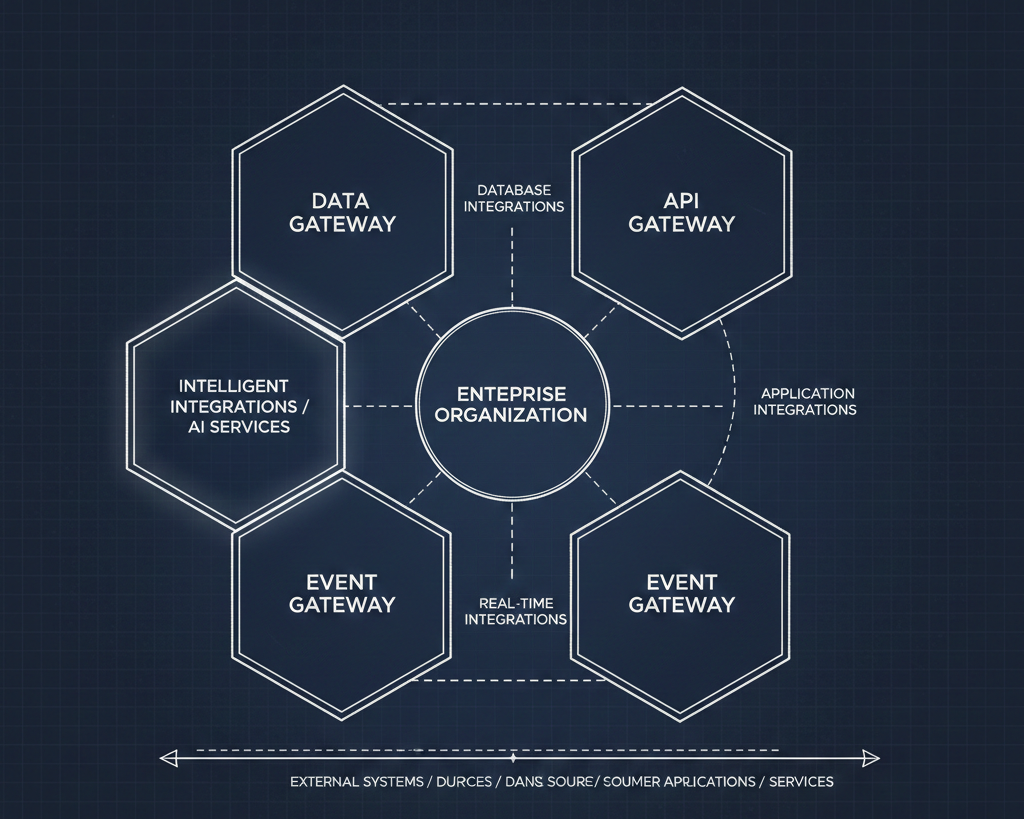
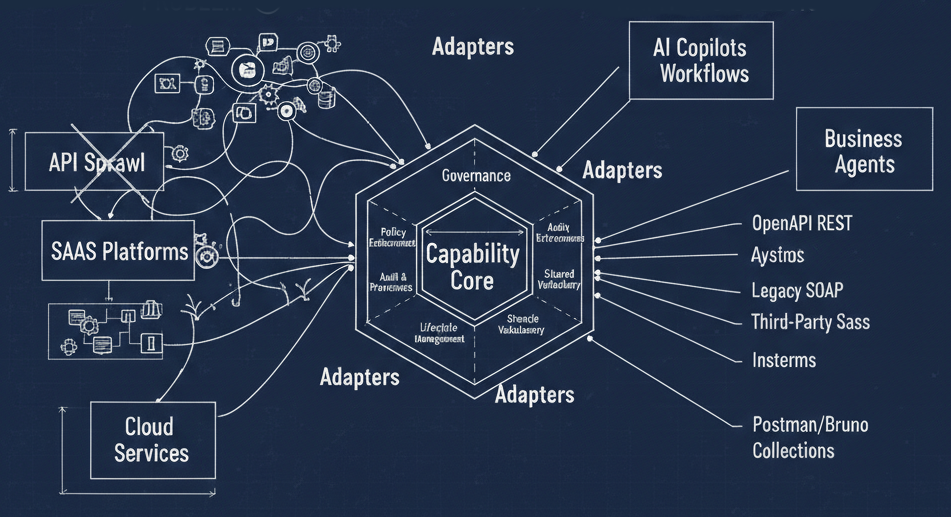
Reusability isn’t flat. It exists simultaneously across knowledge, templates, components, hosted services, and composed systems. Auth0 alone isn’t reusable — the entire chain of identity, configuration, policies, and integration is.
Checkbox-driven scoring models also miss the connection to developer experience and delivery speed. A service can score highly on documentation and support and still do nothing to reduce lead time.
The Missing Link: Developer Experience to Business Outcomes
Leadership wants evidence that reuse increases throughput. Developers want less friction and faster delivery. The missing link is understanding how reuse actually affects lead time.
If reuse doesn’t shorten the time it takes to ship, it doesn’t improve throughput — regardless of how many schemas are shared. Counting reuse activity without measuring its impact on flow violates basic systems thinking.
This gap is made worse by the absence of reuse checks during architecture and solution design. Most teams are never prompted to ask, “Does this capability already exist?” before building something new.
Context, Semantics, and the “It Depends” Reality
Another hard truth: reusability without context is meaningless.
Counting a /contact endpoint across sales and support domains ignores the fact that they represent different business semantics. Measuring reuse without understanding domain boundaries, product strategy, and customer impact leads to metrics that look good but don’t matter.
This is where “it depends” becomes unavoidable — not as an excuse, but as a signal that reusability is multi-dimensional. Without shared ground rules about audience, domain, and perspective, conversations about reuse quickly fall apart.
A More Pragmatic Path Forward
Instead of chasing perfect catalogs or universal scoring systems, a more effective approach starts small and practical:
- Create an API reusability cache — a machine-readable collection of OpenAPI and schema artifacts that helps teams understand what exists.
- Enrich those artifacts with automated analysis and AI-assisted insights.
- Inject reuse awareness directly into developer workflows — editors, GitOps pipelines, API clients, and copilots.
- Produce snackable visuals and narratives that connect technical reality to business language.
- Run low-budget, evolvable proofs of concept that demonstrate value before scaling.
The goal isn’t to centralize control — it’s to reduce friction at the moment decisions are made.
Change Management Is the Real Work
Finally, none of this succeeds without acknowledging organizational scar tissue. Many teams have lived through failed catalog initiatives, abandoned centers of excellence, and governance programs that stalled out.
Champions often lack the authority to drive change but are crucial information spreaders. Leadership needs economic narratives, not technical lectures. Domain experts want substance, not slogans.
API reusability isn’t blocked by ignorance — it’s blocked by history.
Reframing the Question
The most important shift is this: stop asking “How reusable are our APIs?” and start asking:
- Is reuse reducing lead time?
- Is it increasing throughput?
- Is it trusted enough that teams choose it over rebuilding?
- Is it aligned with business capabilities and strategy?
Until those questions are central, reusability will remain a report that floats upward — impressive in slides, invisible in delivery.
And that’s the real reuse problem.