We recently sat down with David Biesack on the Naftiko Capabilities podcast to explore how JSON Schema serves as a critical tool for managing API complexity. The conversation offers a practical look at how a team can build obust workflows around schemas, YAML, and OpenAPI—and why these patterns matter even more in an era of AI agents and MCP servers.
Why JSON Schema Matters for OpenAPI
When OpenAPI 3.1 arrived, it brought full adoption of JSON Schema (specifically the 2020-12 draft) as the standard for defining data models. This wasn’t just a technical nicety—it fundamentally changed how teams can work with API specifications.
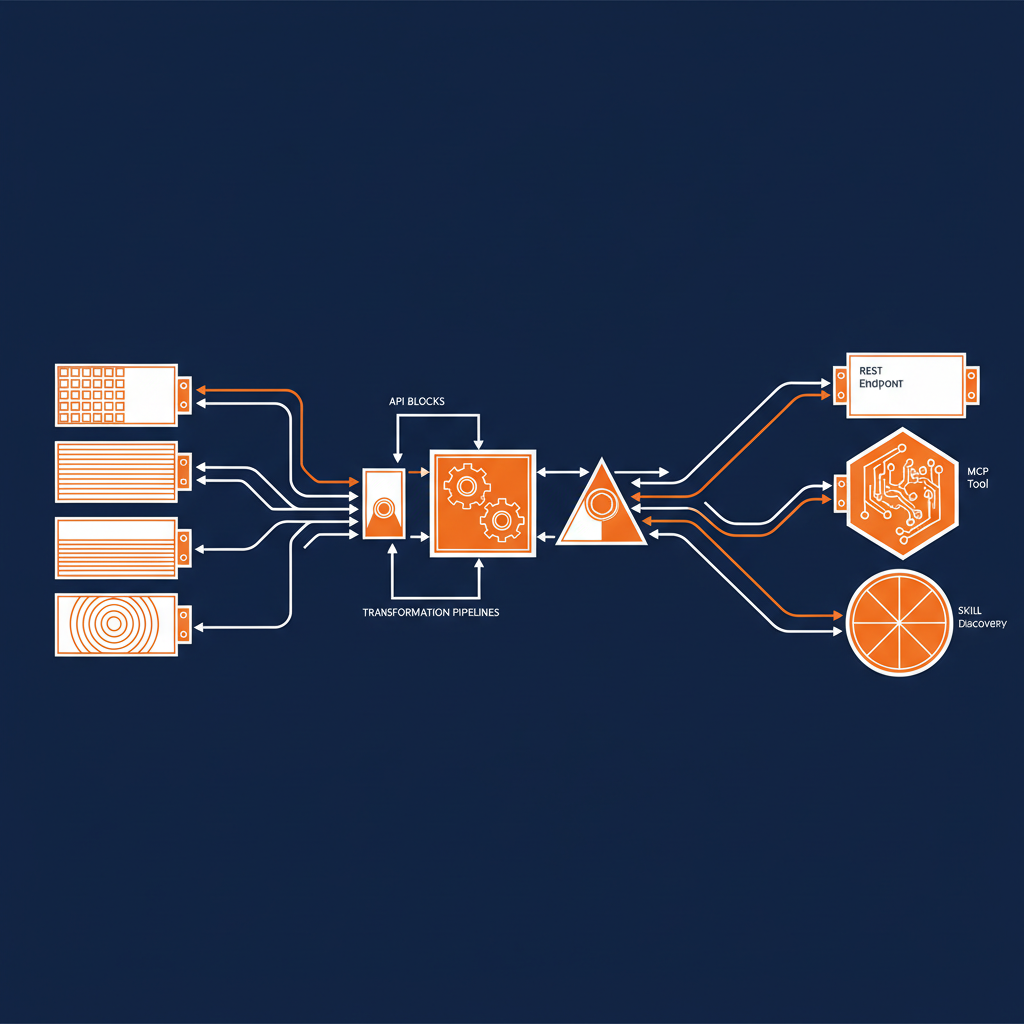
David explained that his team built a tool called OpenAPI ModelGen that extracts all schemas from an OpenAPI document into a standalone bundle. This seemingly simple capability has profound implications: testers can validate request bodies against schemas without understanding the broader OpenAPI structure, and tooling developers can work with data definitions in isolation. The schema becomes a shared contract that different teams can use independently.
The YAML and JSON Balance
One of the perpetual debates in the API space concerns when to use YAML versus JSON. David’s team has found a pragmatic middle ground: author in YAML, process in JSON.
The reasoning is straightforward. Humans write the bulk of API documentation—descriptions, change notes, explanations of what fields mean and why they exist. YAML’s readability makes this work far more pleasant than wrestling with JSON’s quotation marks and strict syntax. But they’re careful to stick with YAML constructs that map cleanly to JSON, avoiding YAML-specific extensions that would break that conversion.
Tools handle the translation. When a pipeline needs to process the spec, it converts YAML to JSON automatically. This gives teams the best of both worlds: human-friendly authoring and machine-friendly processing.
Taming Complexity with References
OpenAPI’s component model allows teams to split complex APIs across multiple files and reuse common elements. David’s team maintains a shared “common” OpenAPI document containing standard elements like error responses based on RFC 9457’s problem+json format. Individual banking APIs—for accounts, transfers, transactions, ACH payments—all reference these common schemas rather than duplicating them.
This modularity is powerful for design but creates challenges downstream. Not everyone consuming an API spec wants to chase references across files. So the team built an open-source tool called API Ref Resolver that bundles everything into a single self-contained document. Backend developers generating code don’t need to understand the component architecture; they just work with the resolved output.
There’s a parallel here to the context window challenges emerging with MCP and AI agents. You need to bundle the right set of paths and schemas together—interwoven and fully resolved—to produce something useful for code generation, agent servers, or whatever the target happens to be.
Extending OpenAPI Where It Falls Short
Perhaps the most interesting part of the conversation concerned OpenAPI extensions. David’s team has built a suite of custom extensions (prefixed with x-aperture) that inject richer metadata into their specifications.
Consider enumerations. JSON Schema enums are just lists of strings with no built-in way to describe what each value means. The x-aperture-enum extension links each enumeration to a labels file containing human-readable names and descriptions. A banking product type isn’t just “checking” or “savings”—it’s a fully documented concept with an English label and explanation of what that classification entails.
Deprecation is another area where standard OpenAPI falls short. Beyond the simple deprecated: true flag, their x-aperture-deprecation extension captures when deprecation was introduced, when removal will occur, and what replacement to use. This gives developers actionable information to update their code before breaking changes land.
Crucially, each of these custom extensions has its own JSON Schema defining valid values. The pipeline validates extension data during processing, catching errors early rather than letting malformed metadata propagate.
The Bigger Picture
What emerges from this conversation is a vision of API management grounded in schemas as the source of truth. JSON Schema provides the foundation; YAML makes authoring accessible; OpenAPI ties everything together; and custom extensions fill the semantic gaps.
These same patterns—modular resources, bundled context, schema-driven validation—are exactly what teams need as they navigate the emerging landscape of AI agents and MCP servers. The context window problem David mentioned isn’t new; it’s the same challenge API designers have been solving with references and bundling for years.
The toolbox is already here, we just have to begin using it consistently across our operations.