The API economy is evolving faster than the tooling, governance, and organizational muscles built to support it. After dozens of conversations with platform teams, API architects, and integration leaders across the enterprise, a pattern has emerged: the same unsolved problems keep surfacing—problems that don't fit neatly into any single vendor's roadmap, and that most organizations are only beginning to articulate.
We cataloged 42 of them. Not feature requests. Not nice-to-haves. These are the structural gaps that stand between where enterprise API and AI strategies are today and where they need to be.
Here's what we found—organized into seven themes that tell a bigger story.
1. The MCP Frontier: Promising Protocol, Missing Plumbing
Model Context Protocol is the most exciting development in how AI agents interact with enterprise systems. It's also wildly immature when it comes to real-world deployment. Teams are excited about MCP, but when they try to operationalize it, they run into walls.
There's no governed approach to using third-party services via MCP servers. Today, any developer can stand up an MCP server that connects an AI agent to a SaaS API—but nobody is asking who approved that connection, what data flows through it, or whether it complies with enterprise security policy. The gap between "it works on my laptop" and "it's production-ready" is enormous.
Securing MCP in developer IDEs is an unsolved problem. Coding assistants like Copilot and Cursor are rapidly adopting MCP, but enterprise security teams have no visibility into what these tools are connecting to, what data they're sending, or how to enforce guardrails without killing developer productivity.
MCP streaming doesn't work with enterprise security infrastructure. Server-Sent Events and long-lived connections break when they hit corporate proxies, WAFs, and API gateways built for request-response patterns. Security teams aren't going to just "turn things off" to make MCP work. The protocol needs to meet enterprise infrastructure where it is.
MCP documentation is a major gap. There's a common assumption that AI agents will "just figure it out" when given access to an MCP server. They won't. Without rich, structured documentation—descriptions of tools, expected parameters, error handling behavior, and usage constraints—agents make bad calls, hallucinate parameters, and burn tokens on retries.
MCP sprawl is already happening. Without central visibility, multiple teams build duplicate MCP server implementations for the same underlying APIs. It's the microservices sprawl problem all over again, except now the duplicates are invisible to platform teams because they live in agent configurations, not deployment pipelines.
Task-oriented MCP tools are what agents actually need—not one-to-one API endpoint mappings. Wrapping every REST endpoint as an MCP tool creates noisy, inefficient agent interfaces. Agents work better with tools designed around tasks and workflows: "create an invoice" instead of "POST /invoices then PUT /invoices/{id}/lines then POST /invoices/{id}/send." Designing good MCP tools is a product design problem, not just an integration problem.
Translating many MCP tools into efficient agent interfaces is its own challenge. When an agent has access to hundreds of MCP tools, it struggles with selection, sequencing, and context. There's no established pattern for creating curated "tool sets" or tiered discovery that helps agents work efficiently at scale.
2. The Agent Identity Crisis
AI agents are the new integration layer—but the identity and authorization infrastructure wasn't built for them.
Agent-to-agent identity propagation and authorization is fundamentally unsolved. When Agent A calls Agent B, which calls API C on behalf of User X, who is authorized? OAuth was designed for human-to-service delegation. We need new patterns for agent chains where trust, scope, and authorization propagate correctly—without creating a security nightmare of over-permissioned service accounts.
Agent evaluation frameworks for API call quality don't exist. How do you know if an agent is making good API calls? Not just "did it get a 200 back" but "did it call the right endpoint, with the right parameters, in the right sequence, to accomplish the user's actual intent?" There's no standard way to evaluate, benchmark, or regression-test agent-API interactions.
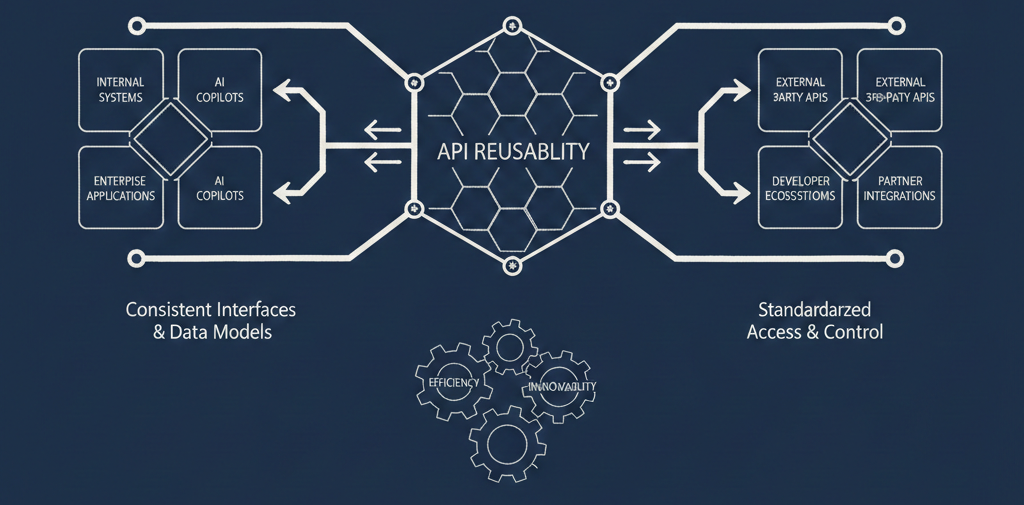
3. API Reuse: Everyone Wants It, Nobody Can Measure It
"Reuse" has been on every enterprise architecture slide deck for a decade. It's still more aspiration than reality, largely because organizations can't agree on what it means or prove that it's happening.
Nobody has defined what "reuse" actually means at the organization level. Is it reuse when two teams call the same API? When they use the same data model? When they share a code library that wraps an API? Without a shared definition, reuse metrics are meaningless—and every team claims they're already doing it.
Reuse can't be quantified or incentivized across domains. Even if you define it, there's no mechanism to measure API reuse across business domains, let alone tie it to incentives. API teams that build reusable services get the same recognition as teams that build one-off integrations. Until reuse connects to budget, headcount, or OKRs, it will remain a talking point.
Discoverability—not governance—is the real barrier to reuse. You can have the best-governed API catalog in the world, and developers will still rebuild from scratch if they can't find what already exists. Discovery needs to be embedded in the developer's workflow—in their IDE, in their AI assistant, in their CI pipeline—not locked behind a portal that nobody visits.
Reuse metrics need to connect to business outcomes. "Number of consumers" is a vanity metric. Enterprise leaders need to see reuse in terms of reduced time-to-market, avoided development cost, and decreased operational risk. Without that translation, API reuse will never get executive attention or sustained investment.
Artifact and data element reuse matters more than API reuse alone. Two APIs that define "customer address" differently create more downstream pain than two teams that don't share an API. Reuse needs to extend to schemas, data models, error formats, and shared definitions—the building blocks beneath the APIs themselves.
Reuse assessment isn't built into architecture review processes. If the question "have you checked what already exists?" isn't a mandatory gate in design reviews, reuse will always be optional. It needs to be a structural part of the review process, with tooling that makes it easy to answer.
4. Governance That Actually Works (And Doesn't Just Mean "More Process")
Governance gets a bad reputation because it's usually implemented as bottleneck-by-committee. The real need is governance that's automated, embedded, and developer-friendly.
Governance rules need to be available in coding assistants via MCP. If developers are writing API code with AI assistance, the governance rules should be in the AI's context—not in a wiki that nobody reads. Imagine a coding assistant that knows your organization's API design standards and applies them in real time. That requires governance-as-MCP.
Governance rule distribution in restricted environments is a real problem. Air-gapped networks, FedRAMP environments, and highly regulated industries can't pull governance rules from the cloud. There's no standard mechanism for distributing, versioning, and enforcing governance policies in disconnected environments.
Governance review tracking and reporting is mostly manual. Who reviewed what? When? What was the outcome? Most organizations track this in spreadsheets or ticketing systems that can't produce aggregate insights. You can't improve what you can't measure, and governance effectiveness is largely unmeasured.
MCP servers that aren't one-to-one with APIs need their own governance model. An MCP server might compose multiple APIs, add business logic, or expose a completely different interface than the underlying services. Existing API governance models don't account for this layer. Who owns it? Who reviews it? What standards apply?
AI-generated code needs security rules applied at creation time. Scanning AI-generated code after it's written and committed is too late. Security guardrails need to be part of the generation process—not a post-hoc gate that creates friction and rework.
Organizational "tribal knowledge" needs to be applied to security scanning. Generic security scanners don't know that your organization has a custom auth library, specific banned patterns, or a legacy service with known quirks. Enterprise-specific context makes the difference between useful findings and noise.
5. The AI FinOps Reckoning
AI services are being adopted faster than finance teams can track the spend—and the bill is coming due.
AI FinOps—cost visibility and control across AI services—is a new discipline that barely exists. Teams are spinning up LLM calls, embedding models, vector databases, and MCP servers across every department. Nobody has a unified view of what it costs, who's spending it, or whether it's delivering value. This is cloud FinOps circa 2015, and we need to learn faster this time.
Third-party API spend management isn't just an AI problem. Organizations have dozens or hundreds of third-party API subscriptions—mapping services, payment processors, data enrichment providers, communication platforms. Most have no centralized view of total spend, no way to identify redundant subscriptions, and no process for renegotiating when usage patterns change.
Centralized credential management for third-party API access is a mess. API keys in environment variables, secrets in config files, credentials shared in Slack. Every third-party integration is a potential security incident. There's no standard enterprise pattern for managing the lifecycle of third-party API credentials across teams.
6. Discovery and Intelligence: The Catalog Problem, Reimagined
The API catalog was supposed to solve discovery. For most organizations, it didn't. The next generation of discovery needs to be smarter, more automated, and AI-native.
Semantic search for API and MCP discovery is essential. Developers don't search for "POST /v2/orders/batch-create"—they search for "create multiple orders at once." Catalog search needs to understand intent, not just match keywords. This requires semantic indexing of API descriptions, parameter names, and usage patterns.
AI-powered enrichment of OpenAPI metadata can fill the documentation gap. Most OpenAPI specs are minimally documented—if they're documented at all. AI can analyze API traffic, code usage, and existing documentation to generate rich descriptions, example payloads, and usage guidance. This isn't about replacing human documentation—it's about creating a baseline that's better than nothing.
Auto-discovery of API artifacts should replace manual catalog registration. If your catalog requires teams to manually register APIs, your catalog is always out of date. Discovery should happen automatically—from API gateways, service meshes, CI/CD pipelines, and code repositories.
A central catalog of third-party APIs is needed for internal discovery. Your organization uses Stripe, Twilio, Salesforce, and forty other external APIs. But there's no internal catalog that tells developers "we already have a Twilio integration, here's how to use it, and here's who manages it." Teams end up building redundant integrations with the same providers.
API documentation needs to be rewritten for AI-first consumption. Documentation designed for human developers in a browser doesn't serve AI agents that need structured, machine-readable descriptions with explicit constraints, error taxonomies, and behavioral contracts. The audience for API docs now includes machines—and they read differently than people do.
Developer sites need to be AI-scrapable and AI-friendly. If your developer portal blocks crawlers, uses JavaScript-rendered content exclusively, or hides critical information behind authentication, AI tools can't help your API consumers. Being AI-friendly is the new SEO for developer experience.
Shadow API gateways need to be discovered and governed. Platform teams manage the "official" gateway, but teams across the org have stood up their own—Kong in a container, nginx as a reverse proxy, cloud-native API gateways in department AWS accounts. If you can't see them, you can't govern them, and you can't secure them.
Evidence-based OpenAPI generation from traffic is more reliable than hand-crafted specs. For APIs that have no spec—or specs that have drifted from reality—generating OpenAPI definitions from observed traffic patterns produces a spec that reflects what the API actually does, not what someone intended it to do three years ago.
7. The Organizational and Structural Gaps
Some problems aren't technical at all. They're about people, incentives, and how work is organized.
API teams need to support copilots—and most aren't structured to do so. Developer experience teams are being asked to make APIs "AI-ready," but they don't have guidance, tooling, or staffing for this new responsibility. Supporting AI agents as API consumers is a different job than supporting human developers, and it requires different skills.
The industry needs unicorns who understand both product and AI. The gap between "product manager who understands APIs" and "AI engineer who understands enterprise integration" is where the most critical design decisions fall. Organizations need people who can bridge both worlds, and they're extraordinarily rare.
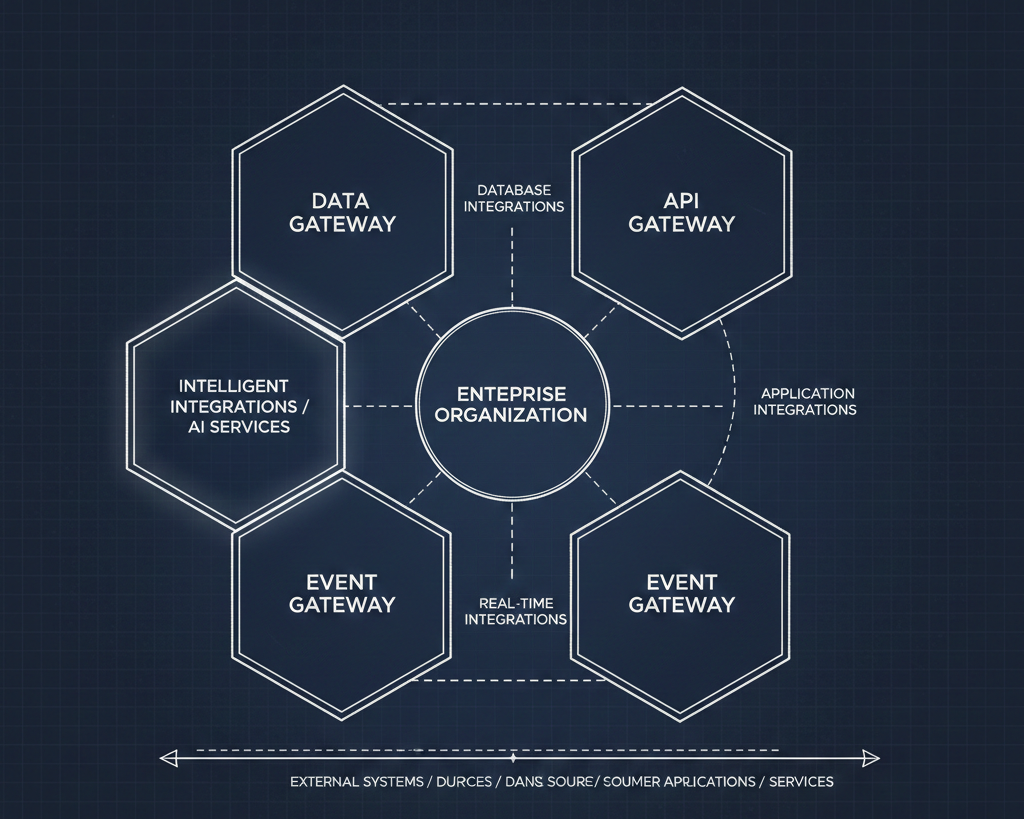
There's no unified view of the integration landscape across all tools. iPaaS over here, MCP servers over there, custom integrations in code, third-party connectors in SaaS platforms. Nobody has a single pane of glass that shows all the ways systems are connected across the enterprise. Without it, every architectural decision is made with incomplete information.
APIs need to be mapped to products and business capabilities. APIs exist to serve business outcomes, but most catalogs organize APIs by team, technology, or domain. Mapping APIs to the products and business capabilities they enable is essential for portfolio management, investment decisions, and M&A due diligence.
Balancing vendor lock-in risk against performance benefits is a constant tension. Every deep platform integration delivers better performance at the cost of switching difficulty. Organizations need frameworks—not just instincts—for evaluating when lock-in is acceptable and when it's dangerous.
Knowing when to exit technologies before cost escalates requires proactive monitoring. By the time a technology exit is urgent, it's already expensive. Organizations need early warning systems that track adoption trajectories, cost trends, and market shifts so they can make exit decisions before they become crises.
Observability across layered, multi-hop integration patterns is nearly impossible. A user action triggers an API call, which triggers an MCP tool, which calls another API, which invokes a webhook, which starts a workflow. When something breaks, good luck tracing it. Distributed tracing wasn't designed for this level of indirection.
Integration platforms need to scale to "10 companies worth of work." Enterprises formed through M&A don't have one integration landscape—they have five or ten. Integration platforms and the teams that run them need to handle the complexity of multiple inherited architectures, redundant systems, and conflicting standards—all while maintaining forward momentum.
Pipeline-less security scanning at the pull request level is the new baseline. Not every code change goes through a full CI/CD pipeline. Security scanning needs to happen at the PR level—fast, inline, and with context about what changed and why. Waiting for a pipeline to catch problems is too slow for the pace of modern development.
So What Do We Do About It?
These 42 problems aren't going to be solved by a single platform, vendor, or framework. They require a combination of new tooling, new organizational practices, and—perhaps most importantly—a shared vocabulary for talking about these challenges.
If you're a platform team leader, start by acknowledging which of these gaps exist in your organization. Not all 42 will apply, but we'd be surprised if fewer than a dozen resonate.
If you're a vendor, this is your product roadmap reality check. The market isn't asking for another API gateway or another observability dashboard. It's asking for solutions to the problems on this list.
And if you're an API practitioner wrestling with any of these challenges, know that you're not alone. These are industry-wide structural gaps—and naming them is the first step toward closing them.
The future of enterprise integration isn't just about connecting systems. It's about doing so with governance, intelligence, and economic discipline that matches the complexity of what we're building.