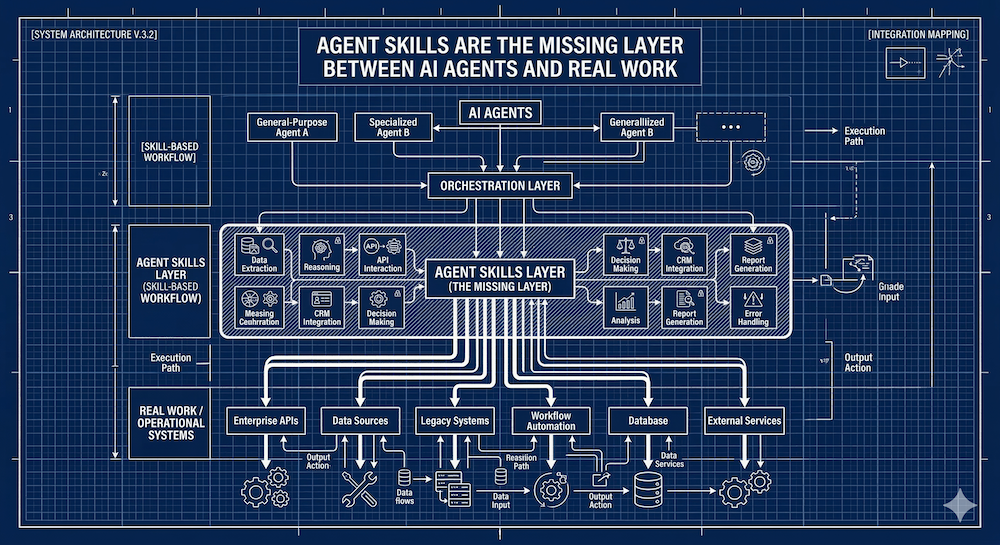
There's a gap between what AI agents can do and what they actually know how to do well. An agent might be capable of writing code, generating documentation, or auditing an API — but without the right context, it's guessing. Agent skills are the answer to that gap.
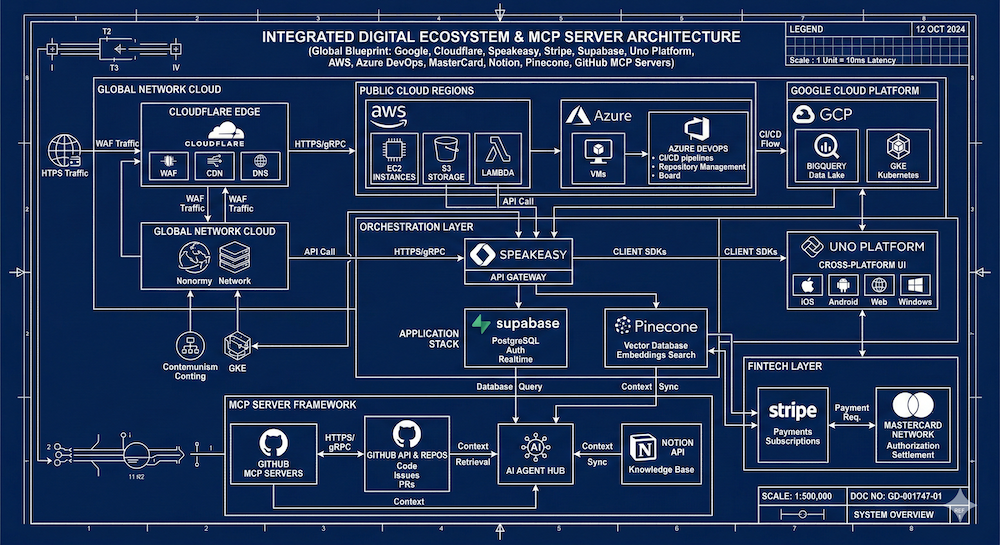
I've been spending the last few weeks deep in MCP research — looking at how Google, Microsoft, and Cloudflare are packaging and distributing developer documentation via MCP servers. This week I turned my attention to agent skills, and I think they deserve their own conversation. They're related to MCP, they overlap in interesting ways, but they're solving a different part of the problem.
So What Is an Agent Skill?
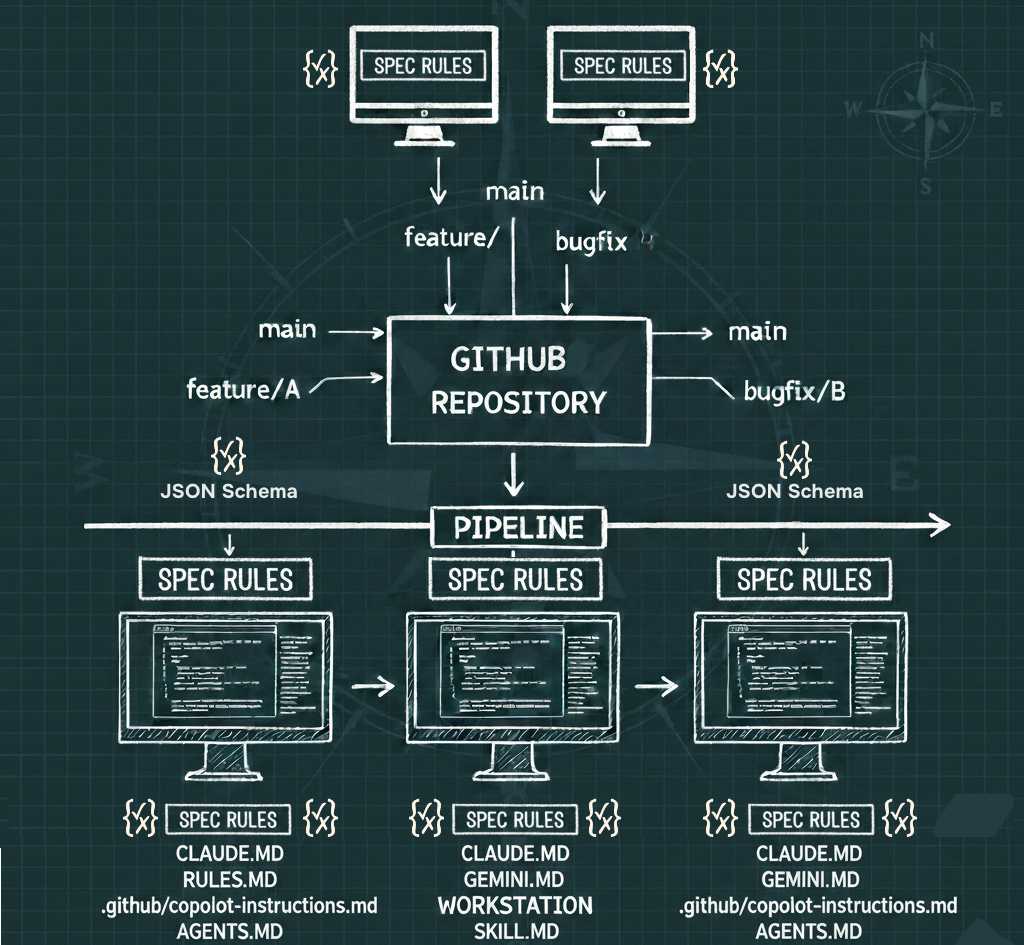
At its simplest, an agent skill is a folder. That's not a reductive take — the folder-based structure is actually one of the most important things about it. Skills are portable, versionable, composable, and lintable because they live in a directory you can put in a Git repo.
A skill folder contains:
- A **SKILL.md** file with a YAML front matter block and markdown instructions
- Optional **scripts** (Python, Bash, or JavaScript)
- Optional **references** — technical docs, domain-specific files like Finance.md or Legal.md
- Optional **assets** — templates, schemas, configuration files, example data, diagrams
The YAML front matter carries metadata the agent uses for discovery: the skill's name, description, compatibility requirements, network access needs, and a list of pre-approved tools the skill is allowed to use. When an agent starts up, it reads the name and description of every available skill — just enough to know what's there. When a task matches a skill's description, the agent loads and uses it.
That's the discovery and activation loop. Simple by design.
Why This Matters More Than It Sounds
The part I find most interesting isn't the scripts or even the instructions — it's the references and assets sections.
References let you attach real documentation to a skill. Not a summary, not a link, but the actual domain knowledge. Want an agent to work with FHIR standards for healthcare APIs? That knowledge can live in a reference file alongside the skill. Working on PSD2-compliant banking APIs? Same idea. The skill becomes a bundled unit of procedural knowledge *and* domain expertise.
Assets extend this further: configuration templates, data schemas, example files, lookup tables, synthetic data sets. A skill stops being just "instructions for an agent" and starts being a complete knowledge package — something closer to a curated, executable documentation artifact.
This is what separates skills from a system prompt or a quick note in a README.
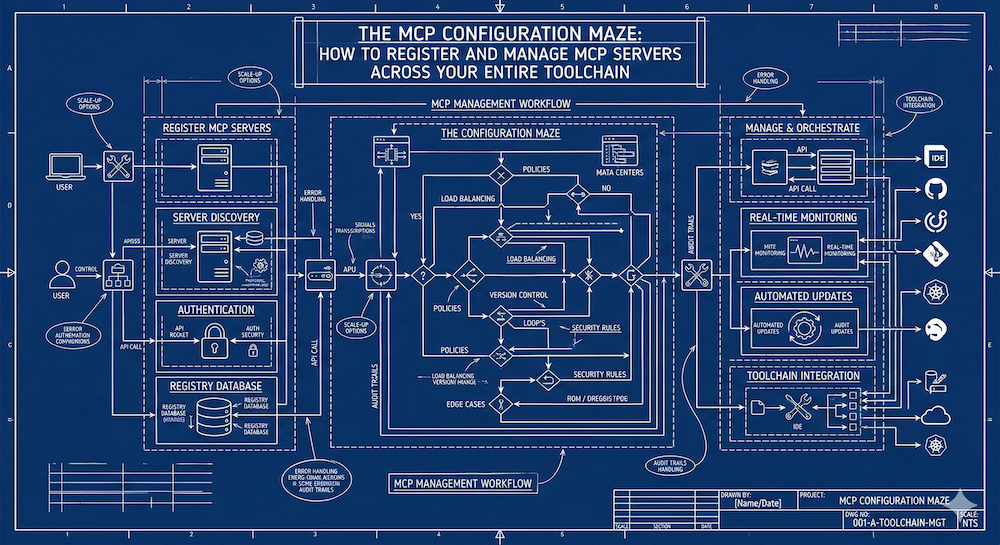
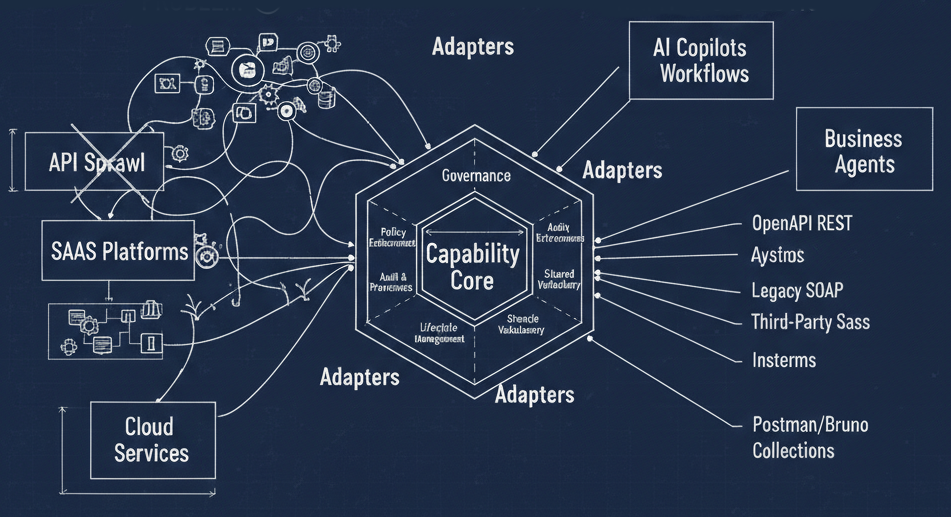
The MCP Overlap (and the Difference)
If you've been following MCP, some of this will feel familiar. MCP also deals with tools, resources, and prompts. And yes, there's genuine overlap — enough that I want to do a proper Venn diagram post soon.
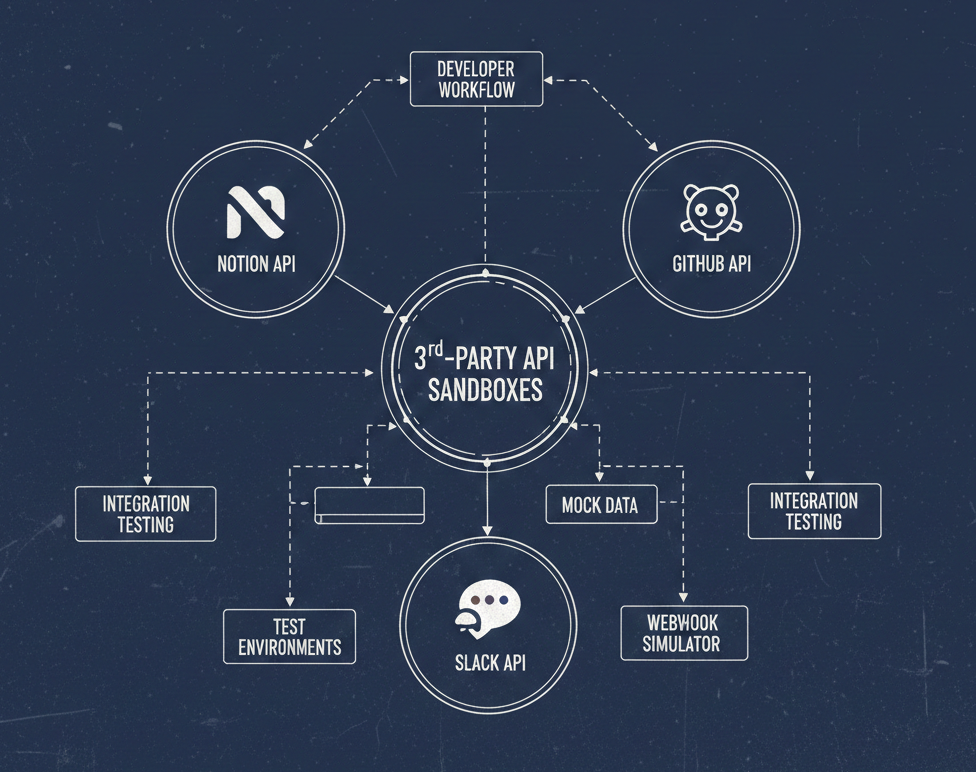
But the key distinction is scope and delivery mechanism. MCP servers are network-deployed, centrally managed, and designed for real-time access to live systems and data. Agent skills are local, file-based, and designed for procedural and contextual knowledge that travels with the agent's workspace.
Think of it this way: an MCP server might give an agent access to your company's live API documentation. A skill gives the agent the procedural knowledge of *how to work with* that documentation — what patterns to apply, what standards to follow, what errors to watch for.
They're complementary. The right question isn't which one you use — it's how you compose them.
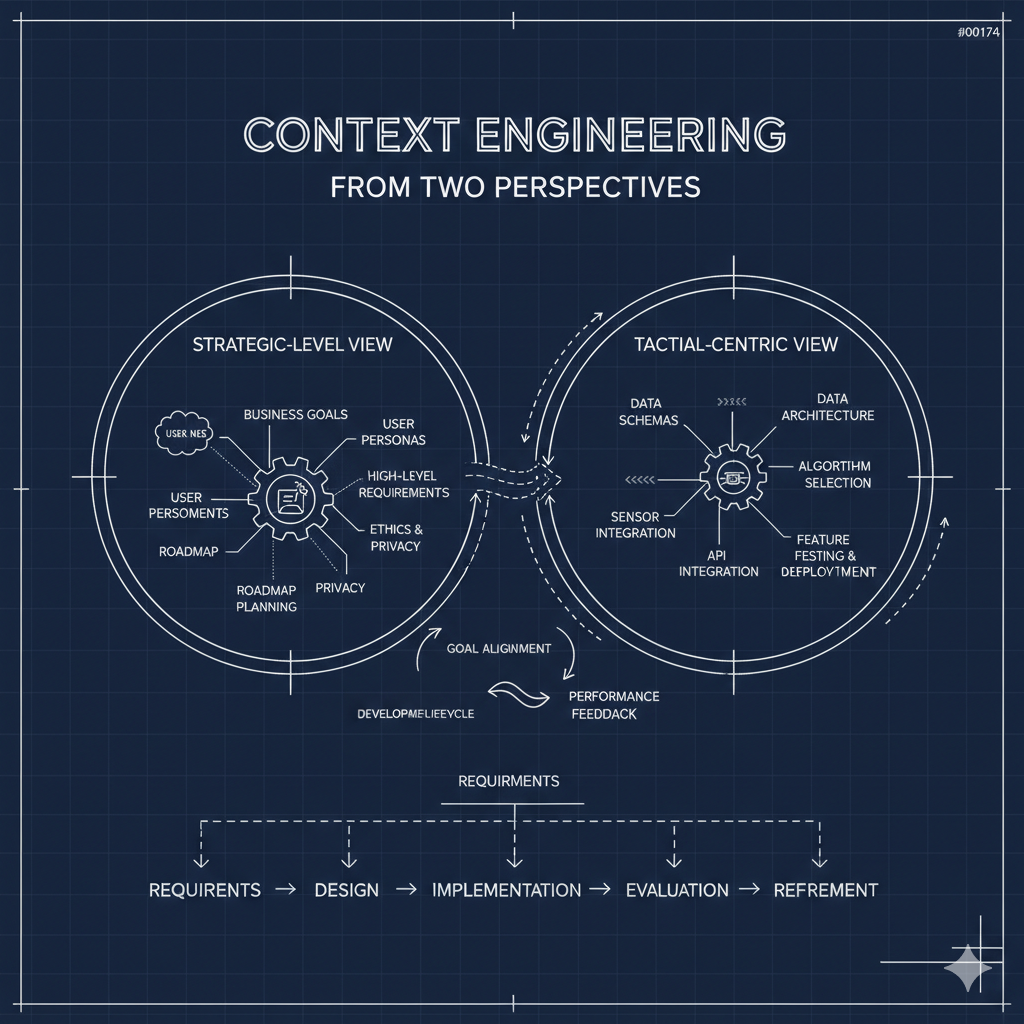
Rightsizing Knowledge for Context
One of the more interesting questions I've been sitting with came from a conversation about the Bentley organization: how do you rightsize what an agent knows based on who's using it?
A junior engineer needs different context than a senior one. A team working on healthcare APIs needs FHIR. A fintech team needs PSD2. A general-purpose skill library doesn't serve anyone well.
This is where the domain-specific reference files become powerful governance tools. You can build a workspace that combines a base set of procedural skills with domain-specific reference overlays — and that composition becomes the bounded context for a particular team or project.
Skills organized by domain, versioned in Git, and composed per workspace is a governance model. It's not glamorous, but it's the kind of operational infrastructure that actually makes AI useful in an enterprise.
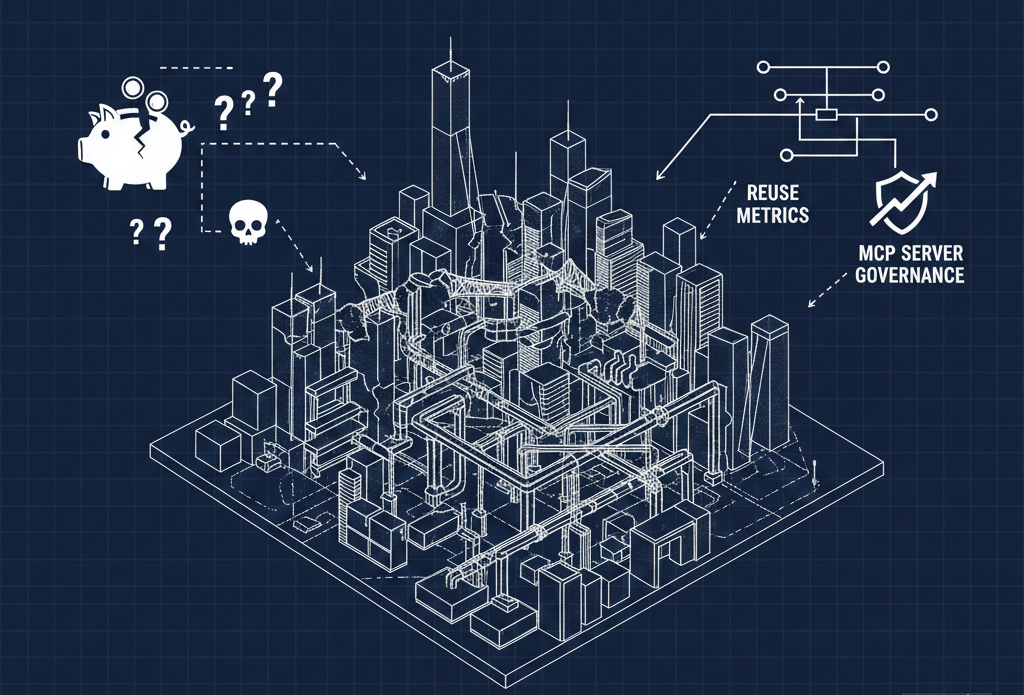
The Governance Question Nobody Is Asking Loudly Enough
Getting teams to consistently use the right rules, the right patterns, and the right documentation has always been the hard part of API governance. We've had this problem with Spectral rules, with style guides, with linting configurations. People grab the latest version off a shared drive and forget to update. Or they customize it locally and drift from the standard.
Agent skills have the same distribution problem. How do you ensure every team is using the current version of the skill? How do you update them? How do you know they're being used at all?
GitOps gives you a foundation — version control, pull requests, audit trails. But the marketplace and plugin layers that some providers are building (more on that in a follow-up) are where this gets interesting. Distribution mechanisms for skills are still being invented, and the decisions being made right now will shape how governable this ecosystem becomes.
That's the conversation I want to keep having.
---
*This is part of an ongoing series exploring how documentation, developer guidance, and API governance are evolving in the age of AI agents. Next up: a survey of how the major providers — Anthropic, Microsoft, Vercel, Cloudflare, and others — are building their skill repositories, and what we can learn from the differences.*