Six governance gaps that are quietly undermining AI adoption across engineering organizations.
Something fundamental shifted the moment AI copilots moved from novelty to daily fixture in developer workflows. The README you wrote for onboarding humans three years ago is now being parsed, followed, and acted upon by autonomous agents — and it was never designed for that job.
Across organizations deploying AI at scale, a cluster of painful realizations is surfacing. The documentation layer — READMEs, CONTRIBUTING guides, AGENTS files, inline comments — has become the de facto control plane for agent behavior. But unlike code, it has no linters, no CI gates, no owners, and no standards. It is infrastructure without an ops team.
What follows is an honest accounting of six governance gaps that are quietly undermining AI adoption across engineering organizations — and a framework for thinking about each one.
"The same organization that enforces 100% test coverage for a two-line config change will push a sweeping AGENTS.md update through an unsanctioned pull request with zero review."
Problem 01 — The Context Layer Has No Owner
In practice: Pat, the head of platforms, is rolling out AI copilots across IDEs. He quickly discovers the repo "context layer" — README, CONTRIBUTING, AGENTS files — has no clear owner. The agent experience is inconsistent repo-to-repo, and nobody is sure who's responsible when behavior breaks.
The context layer is genuinely cross-functional. Engineering wrote the build instructions. DevEx owns the onboarding experience. Security cares about constraint declarations. Documentation teams maintain style. Platform teams care about agent behavior at scale. Nobody is wrong to have a stake — and that's precisely why nothing gets owned.
When everyone owns something, no one does. Repos drift. Agent behavior becomes unpredictable. When something breaks — and it will — the question of "who fixes this?" triggers an org-chart archaeology expedition rather than a fast response.
The organizational risks compound quickly:
- Repos drift into inconsistent, low-trust agent behavior across teams
- Responsibility gaps cause slow fixes when agent behavior becomes unsafe
- Shadow conventions proliferate as teams compensate locally
- No single team is accountable for "agent-ready" context at the organizational level
The fix is not a new team — it's a named steward with a clear mandate, and a cross-functional council for standards. Someone has to own this the way someone owns your API gateway configuration.
Problem 02 — Doc Changes Don't Go Through the Same Gate as Code
In practice: Riley, the head of APIs, can enforce coding standards and CI gates. But she cannot enforce equivalent governance for the Markdown files that shape AI agent behavior — creating an ungoverned control surface that grows more consequential every month.
The asymmetry is striking when you name it. Mature engineering organizations have layered defenses for code: linting, peer review, required approvals, security scanning, CI gates that fail loudly. These weren't built for aesthetic reasons — they were built because ungoverned code changes cause production incidents.
The same organization that enforces 100% test coverage for a two-line config change will push a sweeping AGENTS.md update through an unsanctioned pull request with zero review. The implicit mental model is still "docs are just text." They are not. They are behavioral instructions for systems with real-world effects.
- Silent regressions in agent behavior follow doc edits with no detection mechanism
- Security and compliance exposure via unclear or outdated constraint declarations
- Eroded trust in AI tooling as behavior varies unpredictably repo-to-repo
- Manual review overhead compounds as teams try to compensate without automation
What would doc governance look like if you treated it like code governance? Mandatory structural linting. Required reviewers with domain expertise. CI checks that fail when critical sections are missing or malformed. A "definition of done" for agent-driving documentation that has teeth.
Problem 03 — Repos That Look "Documented" Are Still Agent-Inoperable
In practice: Nina, the context engineer, evaluates repositories that have README, CONTRIBUTING, and AGENTS files present — and still watches agents fail basic setup and contribution workflows because the docs were written for human readers, not machine executors.
There is a distinction that most organizations haven't internalized yet: the difference between descriptive documentation and operational documentation. Human readers fill in gaps with context, inference, and Slack messages. Agents cannot.
"Install the dependencies and run the tests" is fine documentation for a senior engineer who's done it fifty times. It is useless documentation for an agent that needs to know the exact package manager version, the specific test command, whether environment variables must be set first, and what a passing output looks like.
The practical effect is invisible unless you're testing it: agents attempt tasks, fail quietly or noisily, and developers learn not to trust them for the basics. The rot sets in not from missing docs but from docs that feel complete but aren't operationally sufficient.
- Agents fail simple workflows — build, test, run, contribute — wasting developer cycles
- Teams revert to Slack and tribal knowledge, undermining documentation as source of truth
- Onboarding time for new engineers lengthens as agent-assisted setup becomes unreliable
- Senior engineers absorb support burden that agents were supposed to eliminate
Problem 04 — Nobody Has Declared What Agents Are Allowed to Touch
In practice: Morgan, the security and compliance lead, needs repositories to explicitly declare what AI agents are permitted to change. Most repos have no such guidance, leaving agents to infer scope — and inference is not acceptable in a regulated environment.
Agents can propose changes across code, configuration, pipelines, infrastructure definitions, and dependencies. The scope of what they could do grows faster than organizations can reason about what they should do. And in the absence of explicit boundaries, agents default to whatever their training and prompting nudge them toward — not whatever your security policies require.
The problem compounds because "allowed scope" differs meaningfully across contexts. A prototype repository has different risk tolerance than a production service handling PII. An internal tool differs from a customer-facing API. But without encoding these distinctions in the context layer, agents have no way to know which world they're operating in.
- Higher risk of unsafe or non-compliant changes introduced through AI assistance
- Increased friction as agents over-restrict due to uncertainty about their mandate
- Scope decisions get relitigated on every pull request, slowing review
- Audit trails become unusable when agent actions aren't scoped to declared policies
"In the absence of explicit boundaries, agents default to whatever their training nudges them toward — not whatever your security policies require."
Problem 05 — There Is No Continuous Check for Agent Readiness
In practice: Pat wants to scale IDE copilots across hundreds of repositories. He has no repeatable, automatable way to verify that each repo is "agent-ready" — let alone that it stays that way as code and docs evolve.
Agent readiness is multi-layered. You need the right files present, in the right structure, with operationally sufficient content, with explicit scope declarations, using patterns that your toolchain can consistently parse. Any single layer can fail. And repositories are not static — they change constantly, and docs drift without triggering any alarm.
The current state in most organizations is that agent readiness is discovered by failure: a developer tries to use an agent on a repo, it behaves badly or refuses to act, and the gap is diagnosed manually. That's a terrible feedback loop at the scale of hundreds of repositories.
- Inconsistent adoption outcomes across the repository portfolio
- No baseline metric to measure improvement or enforce minimum standards
- Breakages surface late — at the point of use, not at the point of change
- Platform teams can't scale; readiness becomes a manual consulting function
What platform teams need is a continuous, automated signal: pass/fail per repository, with actionable remediation feedback, integrated into the same CI pipeline as everything else. Not a scorecard reviewed quarterly — a gate that runs on every commit.
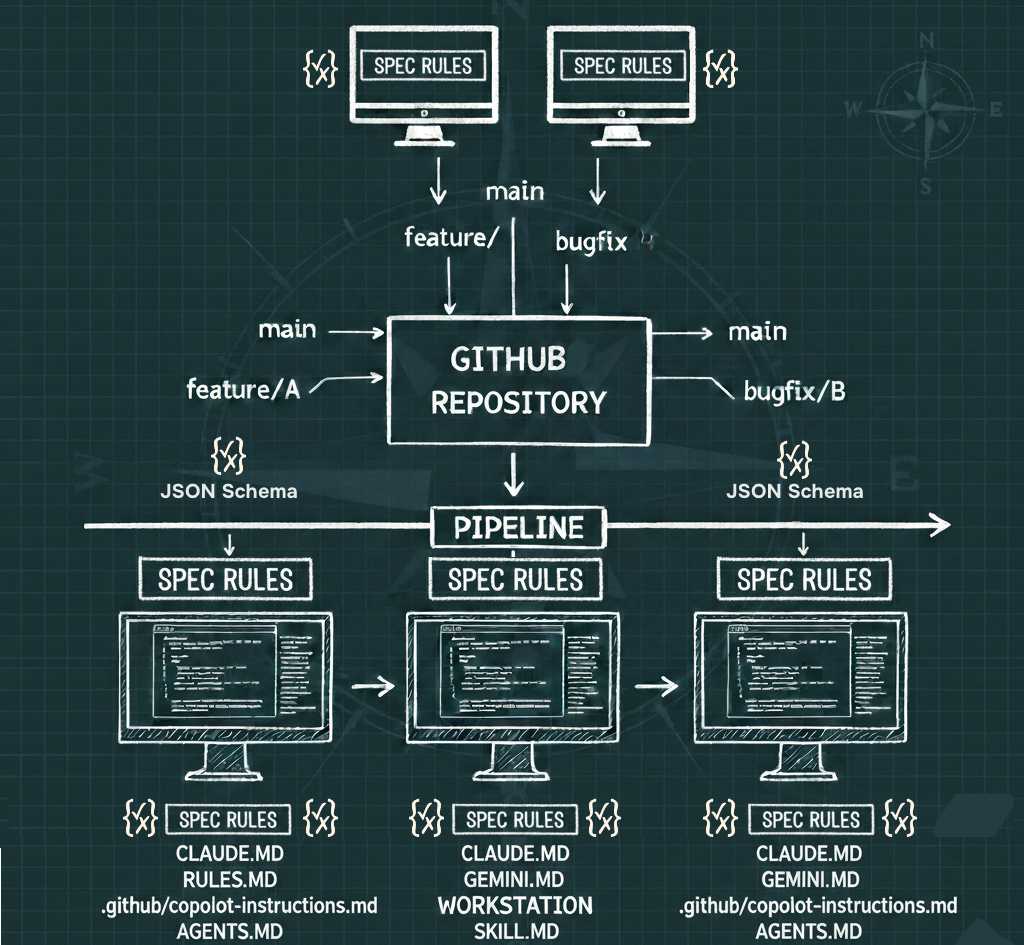
Problem 06 — Inconsistent Markdown Structure Breaks Every AI That Reads It
In practice: Nina evaluates context quality across a portfolio of repositories and finds the same information — build commands, test instructions, contribution requirements — organized differently in every repo, undermining every agent that tries to retrieve it consistently.
Markdown is the de facto interface between repositories and AI systems. Every IDE copilot, every agentic framework, every retrieval system is ultimately pulling from Markdown. The quality of that interface determines the quality of the agent experience.
The problem is not that Markdown is the wrong format. The problem is that "Markdown exists" is treated as sufficient when what agents actually need is predictable, machine-reliable structure. When team A puts prerequisites under ## Getting Started, team B nests them under ### Local Setup, and team C embeds them in a paragraph under ## Contributing, retrieval fails — even when the information is technically present.
Structure reduces variance. Variance amplifies hallucination risk. An agent that can't locate authoritative build instructions will either attempt to infer them (badly) or refuse to act. Neither outcome is acceptable at organizational scale.
- Agents miss critical constraints even when they exist in documentation
- Hallucination rates rise due to ambiguity and inconsistent truth placement
- Context window waste increases as agents scan unstructured long-form documents
- Agent behaviors become non-portable across repositories and organizations
This Is an Infrastructure Problem, and It Needs an Infrastructure Answer
What unites these six problems is a single misprision: that documentation is a human artifact, produced by humans, for humans, governed by human norms like "use your judgment" and "it'll do." That era is over.
The moment AI agents became daily participants in engineering workflows, documentation became executable infrastructure. Infrastructure requires ownership, governance, standards, continuous testing, and explicit scope. The organizations that treat it that way first will have a structural advantage in every AI-assisted workflow that follows.
The good news is that the playbook already exists — it's the same playbook that turned raw code into governed, reliable, scalable software. Apply it to the context layer before the context layer applies its own chaotic logic to your codebase.
The question isn't whether your docs are driving your agents. They already are. The question is whether anyone is driving your docs.